CIS 451 Week 11
Synchronization
- To effectively use multiple threads, you typically need some mechanism for mutual exclusion: Guaranteeing that a
segment of code is run while no other thread is an a corresponding sensitive area.
- For example: Producer thread adds data to a shared array, consumer removes data from that array. The sections
in each thread that access the array must be mutually exclusive
- Producer:
++last; buffer[last] = newItem
- Consumer:
itemToConsume = buffer[last]; --last;
- What happens if code gets executed
c1, p1, p2, c2?
- Conventional solution is to make sure consumer can’t execute it’s “critical section” while consumer is executing
its critical section.
- In a single-processor system an atomic
testAndSet instruction can provide the basis for mutual exclusion
top: tas r1, addr, 1; bnez r1 top- This guards against threads/processes being interleaved.
- This needs to be a special instruction built into the hardware — even in single processor CPU.
- In a multi-core / multiprocessor system the two threads may be running at the same time on different cores.
- Typical algorithms still applicable
- Test and set
- atomic exchange
- fetch-and-increment
- However, these require an atomic mem read / mem write combination. This can be difficult to do efficiently.
- More common approach is not requiring atomicity, but detecting when a read/write pair gets interrupted.
- MIPS and RISC V use
load reserved and store conditional
load reserved loads data from the requested address, then creates a reservation on the memory address
(i.e., stores the address somewhere “safe”)store conditional verifies that the reservation is still in place and returns a 0 if success, non-zero if fail.- To be specific, an intervening store (or invalidation message on the bus) will overwrite the reservation and
cause other stores to fail.
- context switch also invalidates reservation
- “Atomic” exchange of
x4 and data located at addr1
try: mov x3 <-- x4
lr x2 <-- addr
sc x3, addr1 # stores value of x3 *and* x3 gets 0 for success, 1 for failure
bnez x3, try # loop if fails
mov x4 <-- x2
- Register value and memory value should be atomically swapped.
- If another memory access to
addr intervenes, then attempt fails and we try again.
lr places addr in a special register called the reserve register- When cache sees an invalidate message come in, and the address for that message is
the one in the
reserve register, then the subsequent sc must fail.
- Note that the bus access protocol ensures that all processors will agree on which
sc is first (and which others must fail).
li x2 <-- #1
lockit: EXCH x2, 0(addr_of_lock)
bnez x2, lockit
- Kind of like “test and set”
- In other words,
- set
x2 equal to 1.
- Do an atomic swap with the memory address of the lock
- If
x2 comes back with a 0 in it, then the lock wasn’t held previously
and the process now has the lock.
- Otherwise, the lock is in use, try again.
- Problem with doing this in a multiprocessor system?
- The
sc will cause coherency messages.
- The spinning will cause a lot of coherency messages.
- How to improve?
- Do a simple read first. (Don’t try to acquire the lock until you know it’s free).
- The simple read won’t cause traffic.
- Eventually, the write that frees the lock will cause a coherence message to be sent
which will update the cached copy and allow your code to progress to the acquisition stage.
lockit: ld x2 <-- 0(lock_addr)
bnez x2, lockit
li x2 <-- #1
lockit: EXCH x2, 0(addr_of_lock)
bnez x2, lockit
Consistency
- Coherence ensures that multiple processors see a consistent view of memory.
- But, does not answer how consistent.
- Sounds like a simple question; but, it is very difficult.
P1: A = 0; P2: B = 0;
...... .....
A = 1; B = 1;
L1: if (B == 0) ... L2: if (A == 0)
- If writes are serialized and take effect immediately, then it should
be impossible for both
if statements to run (i.e., for both A and B to be 0)
- What if the write invalidate messages are delayed? (Think “cross in the mail”)
- Should this be allowed?
- Under what circumstances?
- Sequential consistency:
- Require that the system behave as if the two codes were “shuffled together”
- This requirement would rule out the situation above.
- Can be implemented by requiring that stores block until all invalidations are complete.
- Can also be implemented by delaying next memory access until the previous one is complete.
- Effective, but can cause delays in busy or big systems (where response would be slow).
- Writes can take 100+ cycles to complete.
- Establish ownership (50+)
- Send invalidate (10)
- Time to receive acknowledgement of invalidate (80+)
- Assume programs are synchronized.
- That is, there is a pair synchronization ops between a write on one processor and a read on another.
(For example, a mutual exclusion lock)
- If there isn’t, there is a data race
- This is a reasonable assumption; because most programs are synchronized.
- Mutex, semaphores, locks, critical sections — all that good stuff from 452.
- It is difficult to reason about programs that aren’t — even if the underlying hardware has sequential
consistency.
- Common approach is to use a relaxed consistency model that can use synchronization to behave as if the
system had sequential consistency.
- Many processors use “release consistency”, which means that consistency is only guaranteed among special
operations that acquire and release locks on shared data.
- RISC also has a
FENCE operation that ensures that all previous operations have completed.
Cross-cutting issues (Section 5.7)
- Compiler optimization
- Currently programs must usually be synchronized, because otherwise it is difficult for compilers to optimize code.
- If the synchronization is done behind the scenes by the consistency model, then compilers don’t know which
reads and writes are shared and which aren’t. This affects
- Reordering
- register allocation
- Whether/how compilers can leverage more precise consistency models is an open research question.
RAID
- Disks have long latency (even SSDs, currently)
- One solution is to read data in parallel by striping data across disks.
- What is the problem?
- One failure ruins all of the data.
- Probability of failure increases exponentially
- Solution RAID
- Redundant Array of Inexpensive/Independant Disks
- Different levels
- RAID 0: Striping. Gives performance but risks failures
- RAID 1: Mirroring.
- RAID 1/0: Striped mirroring. Performance, but uses 2X space or more.
- RAID 2-4: Not typically used.
- RAID 5: Striping with parity.
- RAID 5:
- Simple explanation: One parity disk.
- problem?
- Parity disk becomes a bottleneck
- Solution?
- Rotate the parity block around so it’s not always on the same disk.
Warehouse scale Computing
- Nicholas Carr Quote from 1st page of chapter
- An alternative to SMPs are clusters: Groups of independent networked machines.
- Clusters work well for highly parallelizable problems that require little synchronization.
- Often cheaper than SMPs, because build from commodity hardware.
- The natural extension of a cluster is a Warehouse Scale Computer
- 50,000 - 100,000 servers in a big building.
- Think Google, Amazon, etc.
- Slightly different focus
- Clusters focus on thread level parallelism (parts of a single problem)
- Often using OpenMP or MPI for message-passing synchronization
- Warehouse scale computers focus on request level parallelism
- Think about serving web requests
- These requests tend to be very independent and require very little synchronization.
- Other differences with clusters:
- Clusters tend to be homogeneous (multiple copies of the same HW — like EOS)
- Warehouses tend to be heterogeneous. Either
- to provide different levels of service to different customers, or
- because they can (and it can be cheaper)
- Differences with SMP:
- SMP designers don’t tend to worry about operational cost. Cost is dominated by the cost of the machine itself.
- WHC costs are dominated by operational cost (electricity, cooling)
- With WHC small savings in operational costs add up quickly
- With WHC, location counts. Give examples
- Need population center nearby for staff
- Nearby source of inexpensive power
- Need good Internet connectivity
- Singapore and Australia are close, but Internet bandwidth is lacking
- Low risk of environmental problems (earthquake, tornado, etc.)
- Cool weather is a plus.
- Things like local laws and taxes matter
- WHC must be cost effective at low utilization
- WHC are often way over-provisioned to handle bursts.
- “spare” capacity can’t consume too much power when not in use.
- WHC need a plan to handle failures
- Appropriate redundancy
- Ability to recover
- Job scheduling
- With 50,000+ machines, performance varies greatly between machines — even supposedly homogeneous ones.
- Scheduling is dynamic, watching when jobs finish and assigning new tasks accordingly.
- Not unusual to re-submit a job if it takes too long in case the current CPU/machine is slow because of some
sort of failure.
- Take result of first job to finish.
- Lots of redundancy for performance reasons.
- e.g., data is often replicated for performance reasons (e.g., to be close to where it’s needed)
- Consistency models very relaxed where possible
- Sometimes it is not necessary for all replicas to agree precisely.
- “Eventual consistency” for video sharing
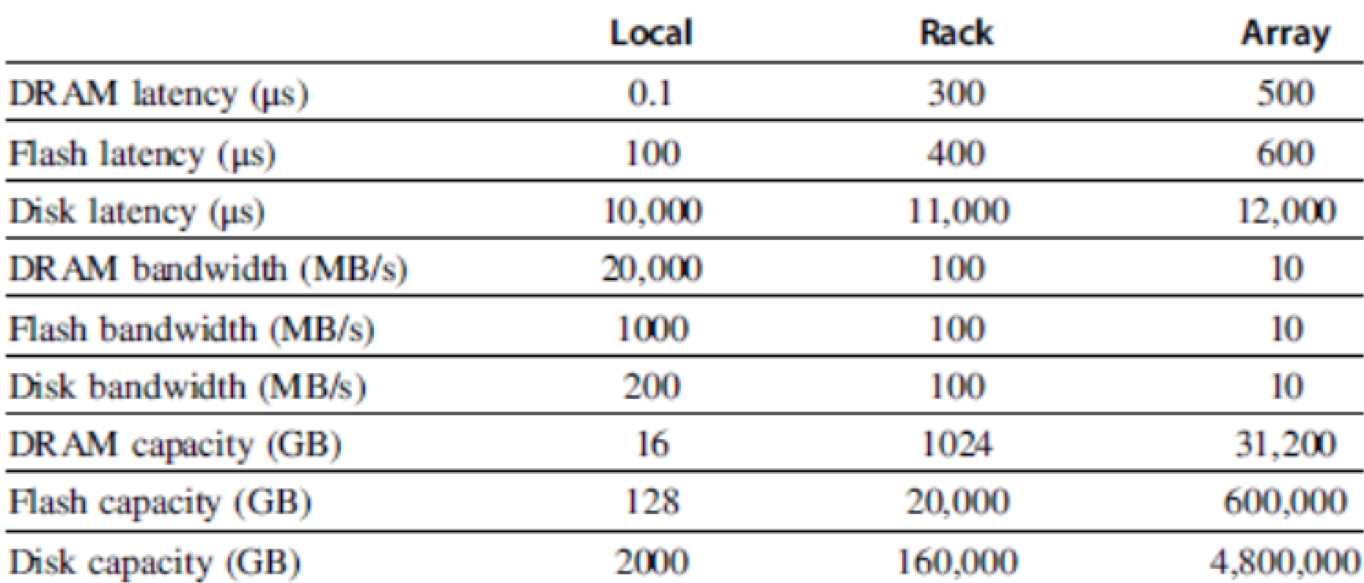
- Typical configuration:
- 10s of machines in a single rack.
- Switch at the top of the rack.
- Groups of racks called “arrays” with a switch for the array
- Entire warehouse comprises many arrays.
- Arrays may even have their own hierarchy.
- This means, of course, that administrators need to take care to place related applications in the same rack to get
best communication time.
- This hierarchy “collapses” the differences in latency between RAM and disk
- Huge difference in latency between RAM and disk within a machine.
- Very small difference at the top of the hierarchy.
- See Figure 6.6
Efficiency and Cost (Section 6.4)
- Infrastructure costs for power distribution and cooling are the majority of the construction costs of a WSC.
- Actual power usage inside a Google Warehouse in 2012:
- 42% to power processors
- 12% to power DRAM
- 14% for disks
- 5% for networking
- 15% for cooling overhead (not sure why term “overhead” used.)
- 8% for power overhead
- 4% miscellaneous
- PUE (Power utilization effectiveness) used to measure efficiency.
- (Total facility power ) / (IT equipment power)
- Sample of 19 data centers showed PUE of 1.33 to 3.03.
- AC ranged from .3 to 1.4 times IT power
- Google improved from 1.22 to 1.12 from 2008 through 2017
- Does not account for performance — smallest PUE is not necessarily cheapest $/operation
- Effects of latency
- Increasing latency had a much larger effect on total time to completion.
- Cutting response time by 30% led to a 70% decrease in total interaction time
- Another study showed a 200ms delay at server produced 500ms increase in time to next click.
- Revenue dropped linear with increase in delay
- User satisfaction also dropped linearly
- Effects lingered
- After 200ms delay, usage was down 0.1% four weeks after latency returned to normal
- 400ms delay produced lingering 0.2% decrease
- This results in the loss of a lot of money
- How to set latency targets in response?
- Can’t just pick average. Need a target for 99% of users below
x
- The very slow ones are lost revenue. At some point, faster than noticeable doesn’t help.
So, you don’t want the very fast ones to “give permission” for slow ones.
- Goals called SLOs Service Level Objectives
Section 6.5
- Economies of scale
- $4.6 per GB per year for WSC vs $26/GB for a data center
- 7.1x reduction in administrative costs (1000 servers/admin vs 140)
- 7.3x reduction in networking costs ($13/Mbit/month vs $95)
- Can also purchase equipment in larger volumes.
- Warehouses tend to serve several customers.
- Even when warehouse built for one primary client, excess is leased out to public.
Why
- Public tends to have different peaks, so resources can be used more efficiently.
- In 2007 many power supplies were only 60% to 80% efficient
Section 6.7 — Example Google Warehouse
- They avoid typical A/C whenever possible
- Hot air forced up and into heat exchanger with cool water
- Water cooled on the roof using evaporation, when possible.
- Finland’s warehouse uses cold water from Gulf of Finland
- Some traditional A/C/ capacity present when necessary.
- Designed to operate at 80, rather than the 65 to 70 of a
traditional data center
- Allows for cooling towers to work in most cases (as opposed to traditional A/C)
- Power delivered as AC to each rack, then 48V DC down the rack to the
individual servers.
- Each warehouse has diesel generators for power failures
- But, they take 10s of seconds to spin up.
- UPS on each rack to fill the gap
- Contracts for continuous diesel delivery for extended outages.